Por que Escolher a Ti Encontrei?
Entregamos SEO de alta performance, engenharia de performance digital e estratégias baseadas em dados que transformam empresas do Rio Grande do Sul. Nossa metodologia combina técnica, conteúdo, autoridade digital e otimização contínua.
Crescimento Contínuo
Aumento real de impressões, cliques e posições no Google com projeção previsível.
Mais Clientes pelo Google
Estratégias avançadas de SEO Local fortalecem sua presença no Maps e nas buscas regionais.

Engenharia de Performance
Melhorias técnicas profundas que elevam Core Web Vitals, velocidade e estabilidade.

Autoridade Digital Real
Backlinks premium, PR digital e conteúdo estratégico elevam sua autoridade no setor.
Reconhecimento na Mídia
A Ti Encontrei já foi citada por veículos nacionais e internacionais, reforçando autoridade, confiança e relevância no ecossistema digital. Veja alguns dos principais destaques.




Quem Somos
Desde 2017, a Ti Encontrei na Web atua com foco em crescimento digital, reunindo SEO estratégico, Google Meu Negócio, criação de sites profissionais e autoridade online para gerar resultados sólidos e consistentes.
Nossa proposta vai além de entregar presença digital. Trabalhamos para posicionar empresas de forma competitiva no Google, fortalecendo visibilidade, reputação e geração de oportunidades reais de negócio.
Combinamos análise, estrutura, conteúdo e performance para desenvolver projetos pensados para negócios que desejam crescer com base técnica, estratégia bem definida e execução profissional.
Resultados Reais
Veja exemplos de evolução em SEO, Google Meu Negócio e performance técnica aplicados a projetos reais de presença digital e crescimento orgânico.

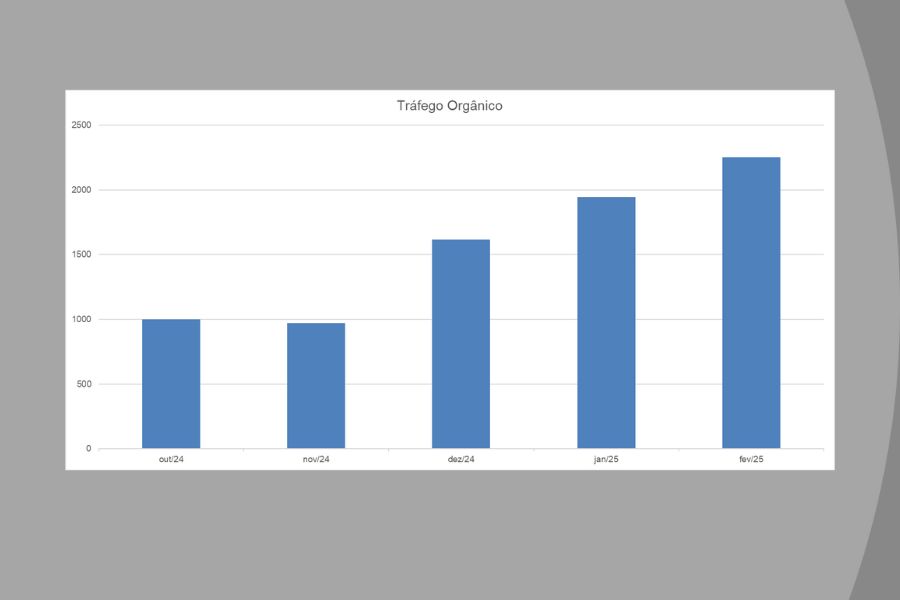
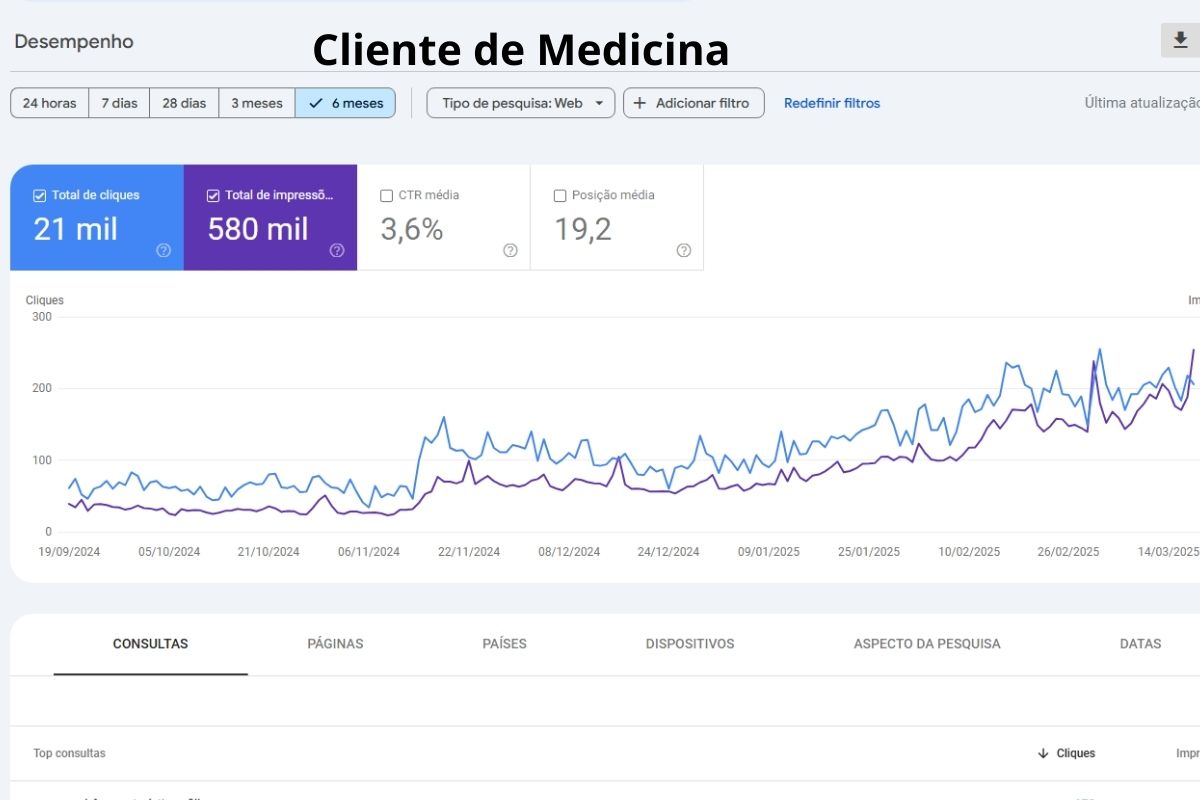
Crescimento de Impressões e Cliques
Evolução orgânica acompanhada pelo Google Search Console, com aumento de visibilidade, impressões e oportunidades de tráfego qualificado.
Mais Clientes pelo Google Maps
Otimização da presença local para aumentar ações de rota, mensagens, ligações e visitas ao perfil da empresa no Google.

Performance Técnica Otimizada
Melhorias em velocidade, estabilidade visual, experiência do usuário e indicadores técnicos que ajudam o site a competir melhor no Google.